 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcclusion-Aware Physics-Semantic Keyframe Selection for Robust Video Editing
May 27, 2026Video editing has recently achieved remarkable progress with diffusion-based generative models, enabling diverse object-level manipulations from natural language instructions. However, existing methods often struggle under occlusion, viewpoint changes, and fast object motion, where unreliable visual observations lead to inaccurate localization, temporal flickering, and inconsistent edits. In this work, we identify the absence of reliable visual anchors as a fundamental bottleneck in occlusion-robust video editing. To address this issue, we propose an occlusion-aware physics-semantic keyframe selection framework that automatically identifies an optimal anchor frame for downstream editing. Specifically, our method evaluates candidate frames from three complementary perspectives: structural completeness for avoiding truncated observations, cycle-consistent tracking stability for measuring physical reliability, and vision-language-based attribute visibility for ensuring semantic clarity. The selected keyframe is then propagated through bidirectional tracking to generate dense spatiotemporal masks, which are used as auxiliary supervision for a diffusion-based video editing backbone. By transforming occlusion handling from explicit reconstruction into reliable anchor selection, our framework enables precise and temporally consistent editing without requiring manual annotations. Extensive experiments on challenging video editing benchmarks demonstrate the effectiveness and high-quality performance of our method.
FineEdit: Fine-Grained Image Edit with Bounding Box Guidance
Apr 13, 2026Diffusion-based image editing models have achieved significant progress in real world applications. However, conventional models typically rely on natural language prompts, which often lack the precision required to localize target objects. Consequently, these models struggle to maintain background consistency due to their global image regeneration paradigm. Recognizing that visual cues provide an intuitive means for users to highlight specific areas of interest, we utilize bounding boxes as guidance to explicitly define the editing target. This approach ensures that the diffusion model can accurately localize the target while preserving background consistency. To achieve this, we propose FineEdit, a multi-level bounding box injection method that enables the model to utilize spatial conditions more effectively. To support this high precision guidance, we present FineEdit-1.2M, a large scale, fine-grained dataset comprising 1.2 million image editing pairs with precise bounding box annotations. Furthermore, we construct a comprehensive benchmark, termed FineEdit-Bench, which includes 1,000 images across 10 subjects to effectively evaluate region based editing capabilities. Evaluations on FineEdit-Bench demonstrate that our model significantly outperforms state-of-the-art open-source models (e.g., Qwen-Image-Edit and LongCat-Image-Edit) in instruction compliance and background preservation. Further assessments on open benchmarks (GEdit and ImgEdit Bench) confirm its superior generalization and robustness.
FineViT: Progressively Unlocking Fine-Grained Perception with Dense Recaptions
Mar 18, 2026While Multimodal Large Language Models (MLLMs) have experienced rapid advancements, their visual encoders frequently remain a performance bottleneck. Conventional CLIP-based encoders struggle with dense spatial tasks due to the loss of visual details caused by low-resolution pretraining and the reliance on noisy, coarse web-crawled image-text pairs. To overcome these limitations, we introduce FineViT, a novel vision encoder specifically designed to unlock fine-grained perception. By replacing coarse web data with dense recaptions, we systematically mitigate information loss through a progressive training paradigm.: first, the encoder is trained from scratch at a high native resolution on billions of global recaptioned image-text pairs, establishing a robust, detail rich semantic foundation. Subsequently, we further enhance its local perception through LLM alignment, utilizing our curated FineCap-450M dataset that comprises over $450$ million high quality local captions. Extensive experiments validate the effectiveness of the progressive strategy. FineViT achieves state-of-the-art zero-shot recognition and retrieval performance, especially in long-context retrieval, and consistently outperforms multimodal visual encoders such as SigLIP2 and Qwen-ViT when integrated into MLLMs. We hope FineViT could serve as a powerful new baseline for fine-grained visual perception.
Accelerating Diffusion Transformers with Dual Feature Caching
Dec 25, 2024



Diffusion Transformers (DiT) have become the dominant methods in image and video generation yet still suffer substantial computational costs. As an effective approach for DiT acceleration, feature caching methods are designed to cache the features of DiT in previous timesteps and reuse them in the next timesteps, allowing us to skip the computation in the next timesteps. However, on the one hand, aggressively reusing all the features cached in previous timesteps leads to a severe drop in generation quality. On the other hand, conservatively caching only the features in the redundant layers or tokens but still computing the important ones successfully preserves the generation quality but results in reductions in acceleration ratios. Observing such a tradeoff between generation quality and acceleration performance, this paper begins by quantitatively studying the accumulated error from cached features. Surprisingly, we find that aggressive caching does not introduce significantly more caching errors in the caching step, and the conservative feature caching can fix the error introduced by aggressive caching. Thereby, we propose a dual caching strategy that adopts aggressive and conservative caching iteratively, leading to significant acceleration and high generation quality at the same time. Besides, we further introduce a V-caching strategy for token-wise conservative caching, which is compatible with flash attention and requires no training and calibration data. Our codes have been released in Github: \textbf{Code: \href{https://github.com/Shenyi-Z/DuCa}{\texttt{\textcolor{cyan}{https://github.com/Shenyi-Z/DuCa}}}}
Betrayed by Attention: A Simple yet Effective Approach for Self-supervised Video Object Segmentation
Nov 29, 2023



In this paper, we propose a simple yet effective approach for self-supervised video object segmentation (VOS). Our key insight is that the inherent structural dependencies present in DINO-pretrained Transformers can be leveraged to establish robust spatio-temporal correspondences in videos. Furthermore, simple clustering on this correspondence cue is sufficient to yield competitive segmentation results. Previous self-supervised VOS techniques majorly resort to auxiliary modalities or utilize iterative slot attention to assist in object discovery, which restricts their general applicability and imposes higher computational requirements. To deal with these challenges, we develop a simplified architecture that capitalizes on the emerging objectness from DINO-pretrained Transformers, bypassing the need for additional modalities or slot attention. Specifically, we first introduce a single spatio-temporal Transformer block to process the frame-wise DINO features and establish spatio-temporal dependencies in the form of self-attention. Subsequently, utilizing these attention maps, we implement hierarchical clustering to generate object segmentation masks. To train the spatio-temporal block in a fully self-supervised manner, we employ semantic and dynamic motion consistency coupled with entropy normalization. Our method demonstrates state-of-the-art performance across multiple unsupervised VOS benchmarks and particularly excels in complex real-world multi-object video segmentation tasks such as DAVIS-17-Unsupervised and YouTube-VIS-19. The code and model checkpoints will be released at https://github.com/shvdiwnkozbw/SSL-UVOS.
Masked Autoencoders are Robust Data Augmentors
Jun 10, 2022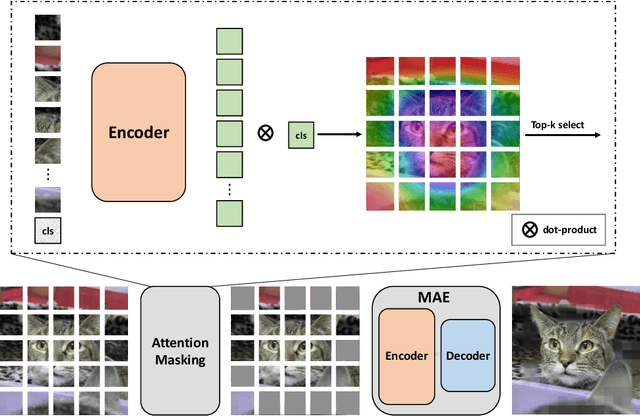
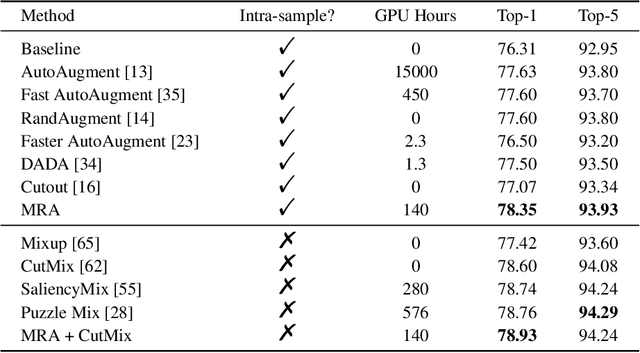
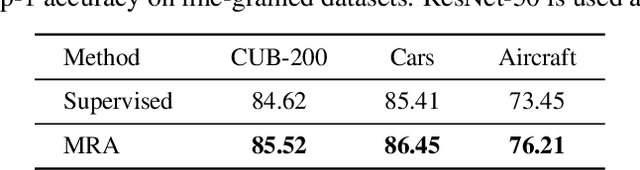

Deep neural networks are capable of learning powerful representations to tackle complex vision tasks but expose undesirable properties like the over-fitting issue. To this end, regularization techniques like image augmentation are necessary for deep neural networks to generalize well. Nevertheless, most prevalent image augmentation recipes confine themselves to off-the-shelf linear transformations like scale, flip, and colorjitter. Due to their hand-crafted property, these augmentations are insufficient to generate truly hard augmented examples. In this paper, we propose a novel perspective of augmentation to regularize the training process. Inspired by the recent success of applying masked image modeling to self-supervised learning, we adopt the self-supervised masked autoencoder to generate the distorted view of the input images. We show that utilizing such model-based nonlinear transformation as data augmentation can improve high-level recognition tasks. We term the proposed method as \textbf{M}ask-\textbf{R}econstruct \textbf{A}ugmentation (MRA). The extensive experiments on various image classification benchmarks verify the effectiveness of the proposed augmentation. Specifically, MRA consistently enhances the performance on supervised, semi-supervised as well as few-shot classification. The code will be available at \url{https://github.com/haohang96/MRA}.
Semantic-Aware Generation for Self-Supervised Visual Representation Learning
Nov 25, 2021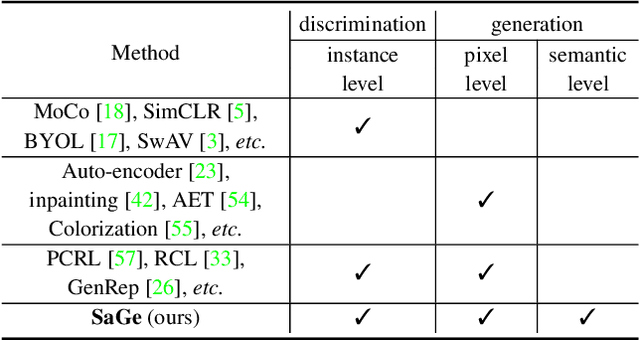
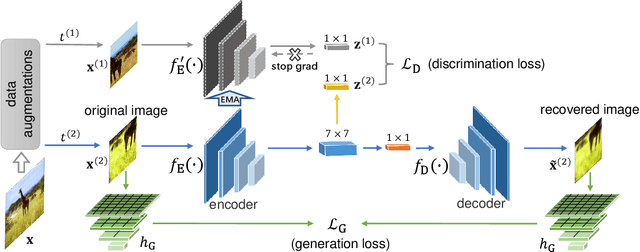

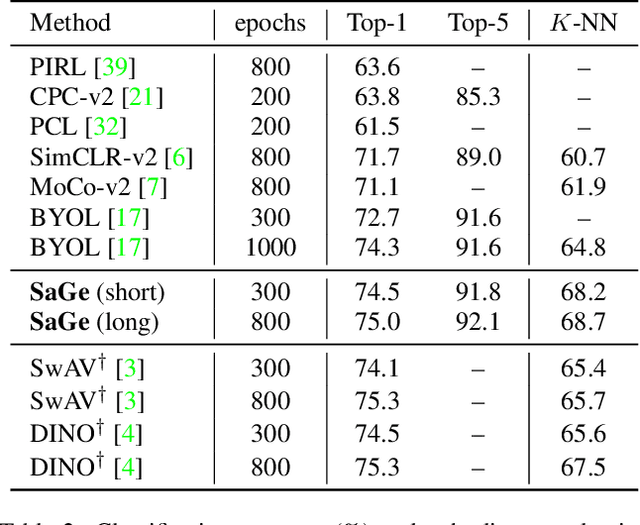
In this paper, we propose a self-supervised visual representation learning approach which involves both generative and discriminative proxies, where we focus on the former part by requiring the target network to recover the original image based on the mid-level features. Different from prior work that mostly focuses on pixel-level similarity between the original and generated images, we advocate for Semantic-aware Generation (SaGe) to facilitate richer semantics rather than details to be preserved in the generated image. The core idea of implementing SaGe is to use an evaluator, a deep network that is pre-trained without labels, for extracting semantic-aware features. SaGe complements the target network with view-specific features and thus alleviates the semantic degradation brought by intensive data augmentations. We execute SaGe on ImageNet-1K and evaluate the pre-trained models on five downstream tasks including nearest neighbor test, linear classification, and fine-scaled image recognition, demonstrating its ability to learn stronger visual representations.
Motion-aware Self-supervised Video Representation Learning via Foreground-background Merging
Sep 30, 2021



In light of the success of contrastive learning in the image domain, current self-supervised video representation learning methods usually employ contrastive loss to facilitate video representation learning. When naively pulling two augmented views of a video closer, the model however tends to learn the common static background as a shortcut but fails to capture the motion information, a phenomenon dubbed as background bias. This bias makes the model suffer from weak generalization ability, leading to worse performance on downstream tasks such as action recognition. To alleviate such bias, we propose Foreground-background Merging (FAME) to deliberately compose the foreground region of the selected video onto the background of others. Specifically, without any off-the-shelf detector, we extract the foreground and background regions via the frame difference and color statistics, and shuffle the background regions among the videos. By leveraging the semantic consistency between the original clips and the fused ones, the model focuses more on the foreground motion pattern and is thus more robust to the background context. Extensive experiments demonstrate that FAME can significantly boost the performance in different downstream tasks with various backbones. When integrated with MoCo, FAME reaches 84.8% and 53.5% accuracy on UCF101 and HMDB51, respectively, achieving the state-of-the-art performance.
Bag of Instances Aggregation Boosts Self-supervised Learning
Jul 04, 2021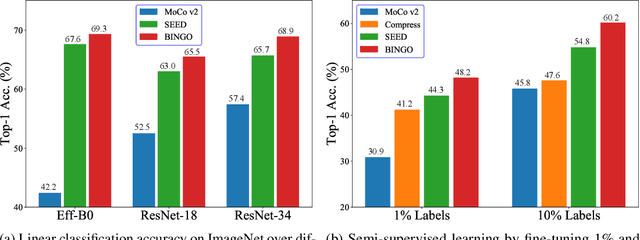
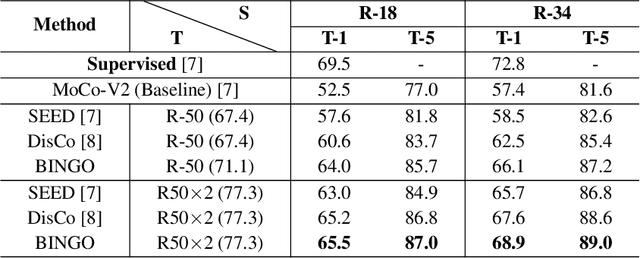
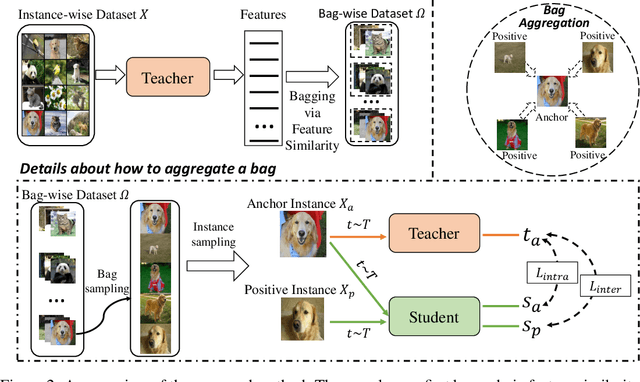
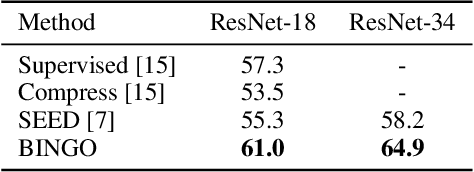
Recent advances in self-supervised learning have experienced remarkable progress, especially for contrastive learning based methods, which regard each image as well as its augmentations as an individual class and try to distinguish them from all other images. However, due to the large quantity of exemplars, this kind of pretext task intrinsically suffers from slow convergence and is hard for optimization. This is especially true for small scale models, which we find the performance drops dramatically comparing with its supervised counterpart. In this paper, we propose a simple but effective distillation strategy for unsupervised learning. The highlight is that the relationship among similar samples counts and can be seamlessly transferred to the student to boost the performance. Our method, termed as BINGO, which is short for \textbf{B}ag of \textbf{I}nsta\textbf{N}ces a\textbf{G}gregati\textbf{O}n, targets at transferring the relationship learned by the teacher to the student. Here bag of instances indicates a set of similar samples constructed by the teacher and are grouped within a bag, and the goal of distillation is to aggregate compact representations over the student with respect to instances in a bag. Notably, BINGO achieves new state-of-the-art performance on small scale models, \emph{i.e.}, 65.5% and 68.9% top-1 accuracies with linear evaluation on ImageNet, using ResNet-18 and ResNet-34 as backbone, respectively, surpassing baselines (52.5% and 57.4% top-1 accuracies) by a significant margin. The code will be available at \url{https://github.com/haohang96/bingo}.
Multi-dataset Pretraining: A Unified Model for Semantic Segmentation
Jun 08, 2021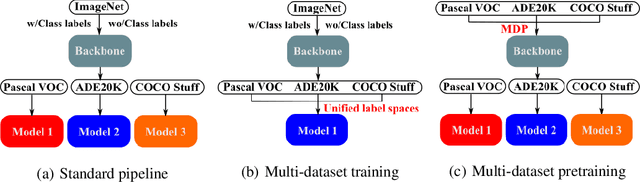
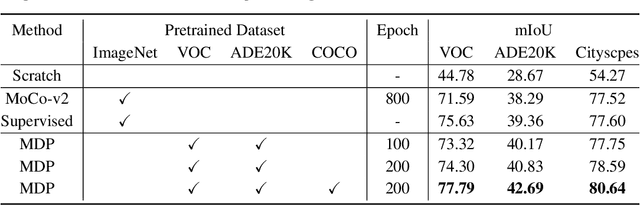
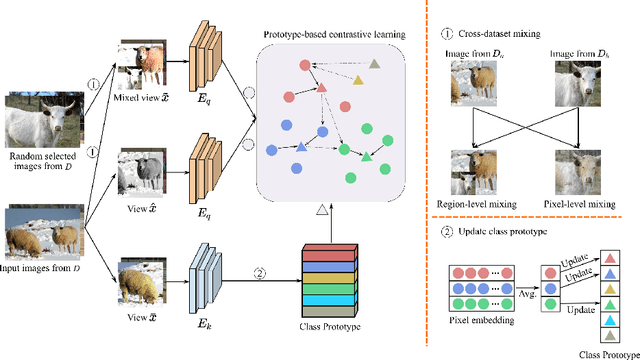
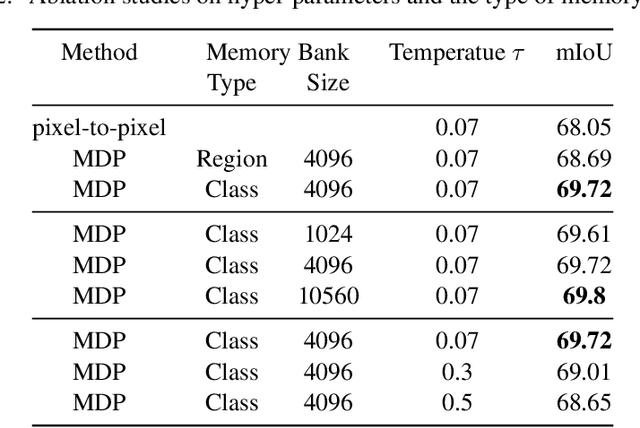
Collecting annotated data for semantic segmentation is time-consuming and hard to scale up. In this paper, we for the first time propose a unified framework, termed as Multi-Dataset Pretraining, to take full advantage of the fragmented annotations of different datasets. The highlight is that the annotations from different domains can be efficiently reused and consistently boost performance for each specific domain. This is achieved by first pretraining the network via the proposed pixel-to-prototype contrastive loss over multiple datasets regardless of their taxonomy labels, and followed by fine-tuning the pretrained model over specific dataset as usual. In order to better model the relationship among images and classes from different datasets, we extend the pixel level embeddings via cross dataset mixing and propose a pixel-to-class sparse coding strategy that explicitly models the pixel-class similarity over the manifold embedding space. In this way, we are able to increase intra-class compactness and inter-class separability, as well as considering inter-class similarity across different datasets for better transferability. Experiments conducted on several benchmarks demonstrate its superior performance. Notably, MDP consistently outperforms the pretrained models over ImageNet by a considerable margin, while only using less than 10% samples for pretraining.